Price drop tracker system design
Design a system to track the price change in product listed on Amazon.com and alert to users if change in price meet the criteria.
User can watch for following in terms of price change
- Relative Price Change: User can set a price drop percentage and should get notifies if percentage price drop to that level.
- Absolute price drop to x: User can set a price target value and should get notifies if price drops to that level.
User should be notified as soon as product price change is detected.
There are two types of system design on price tracker
#1 Server driven price drop criteria
- User intent to subscribe product price drop
- Server tracks the price drop and notifies all the subscribed users.
#2 User driven price drop criteria
- User intent to subscribe product price drop as per their own criteria
- Server keep checking every user’s criteria and only notify to that user if condition match.
In this design, we are going to focus on #2 but will keep design flexible to support both.
We should consider following scale to handle traffic and optimal design
- Support 1+ million active users
- Each user can subscribe up to 100 products
- Globally we should support 10+ million products
High level System design
Following is high level system design for price drop checker system.

On high level we have following systems
- Crawler: It crawls products for price changes.
- Price Check Systems: It detects the product price drops as per user config and generate events.
- Product Subscription Service: It exposes API to allow user to subscribe for products.
- Alerts System: It takes care of sending alerts to user.
Following is high level flow
- User request for product price drop subscription.
- Crawler system fetch product prices every one hour and publish events to
ProductPriceQ. - Price checker system fanout to each user and run check to verify if price drop matches the user’s subscription request. If it does then publsih event to
AlertsQ. - Alerts Queue handler takes care of sending alerts to user.
Let’s go through each systems in details.
Product Subscription Service
It exposes following API which allow user to subscribe for product price drop alerts.
POST /products/<product_id>/subscription
Request {
UserId: xxx
PriceChangeThreshold: x%
PriceValueThreshold: xxx
}
Response {
Status: OK
}It writes user subscription request into ProductSubscriptions table. Following is schema for this table.
ProductId UserId PriceChangeThreshold PriceValueThreshold CreateTimestamp
xxx xxx xxx xx xxxPrimary Key: ProductId + UserId
ShardKey: ProductId
Product Crawler
Product crawler will take care of scanning product price changes. We have two choices here.
- Call eCommerce API to get the product details.
- Let eCommerce to call our pre-registered callback in case of change in any price.
If eCommerce support #2 option then it makes overall design cleaner and we can produce alert near realtime.
If #2 is not available then we will have to make eCommerce API on certain interval. Let’s design our system based on #1.
Following is key feature for crawler.
- Be polite while making HTTP call to target eCommerce server.
- Handle duplicate products to avoid hitting target server for the same product.
- Design to rescan product to get the latest price.
- Cleanup the product that doesn’t exist anymore.
- To discover new products, leverage the similar products API from eCommerce server.
Following are overall design for product price checker crawler.
Product Price Queue
There are two ways to initialize this queue.
- On demand: We can only scan the product if user has shown interest.
- Scan all product: We can scan all the product and be ready with product data.
#1 has works well for small scale. However if user base grows then #2 become a better solution. For the sake of discussion, we will go with #2 approach here.
We can initialize ProductPriceQueue with initial list of products we would like to start crawling. Handler for this queue does following
- Make rpc call to eCommerce to get the product price details.
- It writes new price details into
ProductPriceHistoriestable only if new price is not same as previously captured price. - If it discover that product price is changed then it will publish message into
ProductPriceQueueto notifyPrice Checker Systemto take care of change in price. - On success publish message into
RelatedProductsQueueto discover new products. - It will also enqueue new message for the same product into
ProductPriceQueuewith delay ofxhours to add gap before processing same product again.
Following is schema for ProductPriceHistories table.
ProductId Timestamp Price
xxx xxx xxxPrimaryKey = ProductId+Timestamp
ShardKey = ProductId
How to discover price changed?
It can run following query to read the last price seen for this product.
SELECT Price
FROM ProductPriceHistories
WHERE ProductId= xxx
ORDER BY TIMESTAMP DESC
LIMIT 1Use the lastPrice and compare with current price to detect if there is any change.
But above query will not be efficient as it scans all the historical prices for the product. Since our goal is to only read the last price therefore we can add ProductLastPrice table and always use this table for comparison. Following will be schema for this table.
ProductId CurrentPrice UpdatedAt
xxx xxx xxxPrimaryKey = ProductId
ShardKey = ProductId
Now we can run primary key based query to read the last scan price.
SELECT Price
FROM ProductLastPrice
WHERE ProductId= xxx Note: We will have to make sure to run idempotent query to handle error retry. This can be done including timestamp as condition while updating this table.
Related Products Queue
Handler for this queue takes care of discovering new products. Following high level implementation for this handler.
- Makes rpc call to get the similar product details.
- It then lookup into
DuplicateProductstable to check if we discover any new products that needs to scan. - If it discover new product then it will publish it into
ProductPriceQueuewith predefined delayed delivery.
Politeness design while making rpc call to eCommerce server
Since there is going to be a single eCommerce server therefore we need to be really sensitive to increase traffic to server. We can take following approaches.
- User-Agent Identification: We should specify the user-agent has crawler so that server can understand who is accessing their side and potentially tailor their response.
- Delay Between Requests: We should leverage delayed delivery message delivery to add gap between next processing of same product.
- Handle Errors Gracefully: Implement error handling mechanisms to deal with HTTP status codes like 404 (Not Found), 500 (Internal Server Error), and rate limiting responses. If a request fails, first understand the error code and if error is retry-able then only retry that also after a suitable delay.
- Rate Limiting: We should leverage the queue partition technique with fixed number of partition along with control rate to process the each product to have determinist outbound traffic to eCommerce system.
Following is design for Crawler to handle politeness.
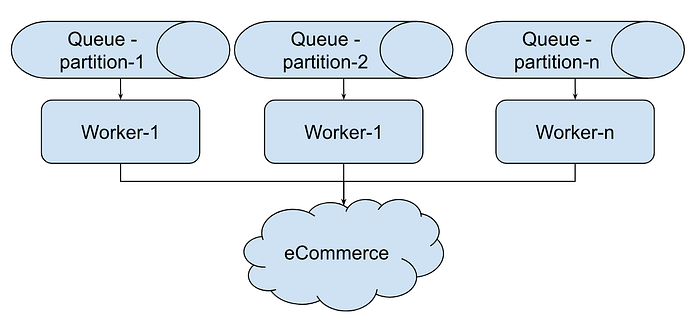
Let’s estimate these numbers.
No of products = 10 million
QPS supported by eCommerce = 1000 qps
Number of workers = 1000
Time to scan all the products =10million/1000/(60*60) = 2.7 hours ~ 3 hours (consider delayed delivery as well will add some delay for next call).
It means in worst case, we will have 3 hours of stale data in our server.
Do we need to worry here?
Yes if we don’t design to match the target server architecture. eCommerce like Amazon doesn’t have concept of global qps. Amzon has partitioned their infra based on different geo location. User access pattern is also different due to time zone difference, product availability, users traffic etc.
For example, 1+ million user doesn’t mean all will be accessing our system same time. May be x% users are from us-east-zone, y% from us-west-zone, z% from eu-zone, p% from south-america-zone, q% from africa-zone, s% from asia-zone etc.
It means we should also consider our scan target to match these geo located users. Let’s say one of the hot zone serve 30% traffic. It means we only need to focus on scanning 3million product.
Time to scan all the products =3million/1000/(60*60) ~ 50 minutes ~ 1 hours
As you see, we can reduce our scan frequency if we match the target server geo location sharding. Following is design to showcase zone based partitions.
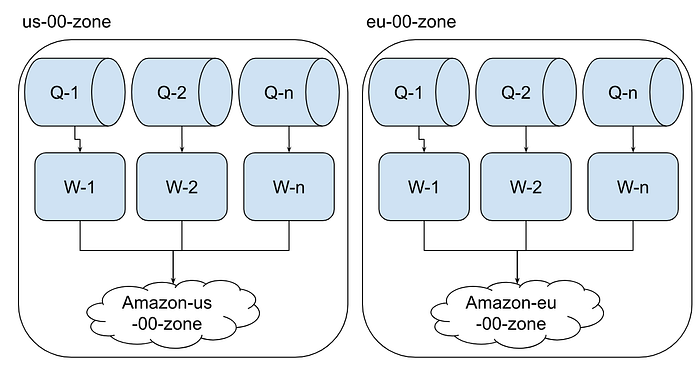
Price Checker System
Price checker system will take care of calculating if there is a drop in price then notify the alert system. Following are design for this system.
Product Price changed Queue
A message will be published to this queue if price change was detected by the crawler system. Since our system is required to calculate the drop alert based on user requested threshold therefore we first need to fanout this message to all subscribed users for the product.
Following is schema of message in this queue.
{
ProductId: xxx
PublishTimestamp: xxx
Payload: {
ProductId: xxx
CurrentPrice: $xxx
PriceTimestamp: xxxx
LastPrice: $xxx
}
}Handler for this queue will do following.
- Read the list of subscribed users from
ProductSubscriptionstable. - Publish message into
UserPriceDropQueuefor further processing.
User Price drop queue
Following is the schema for this queue.
{
UserId: xxx
PublishTimestamp: xxx
Payload: {
ProductId: xxx
CurrentPrice: $xxx
PriceTimestamp: xxxx
LastPrice: $xxx
UserId: xxx
PriceChangeThreshold: x%
PriceValueThreshold: xxx
}
}Handler for this queue will do following.
- Calculate the price value based drop in price.
- Calculate the price changed threshold based drop.
- If it satisfy the threshold limit then publish message to
AlertsQueueotherwise drop it.
Alerts system
Alert system will take care of notifying user about the price drop. Based on the user preference, it will notify either based on email or mobile push notification or realtime browser based notification.
Hope you have enjoyed this design. Feel free to share your feedback. Enjoy learning :-)
