Metrics Monitoring and Alerting system
Design a scalable metrics monitoring to collection system metrics as well as custom metrics as needed by the business.
Following are few example of system metrics
- CPU load
- Memory usage
- Disk consumptions
- Request per seconds of RPC service
- RPC service latency
Following are few examples of custom metrics
- Count number of users as per locale
- End to end latency of message delivery in chat message, starting form user posted message and the time it was delivered to the recipients.
System should also generate alerts based on metrics. Following are few examples.
- Generate alert if RPC error rate is greater than threshold value.
- Generate alert if CPU usage of a server exceed the threshold value.
- Generate alert if a custom metrics to count login retry exceeds the limit.
These alerts should be send to emails, or text message to phone or PageDuety or make Webhooks http calls.
Note: In this design we are focusing alerting based on data captured by monitoring system. Alerting should not be based on server or access logs.
High level system design
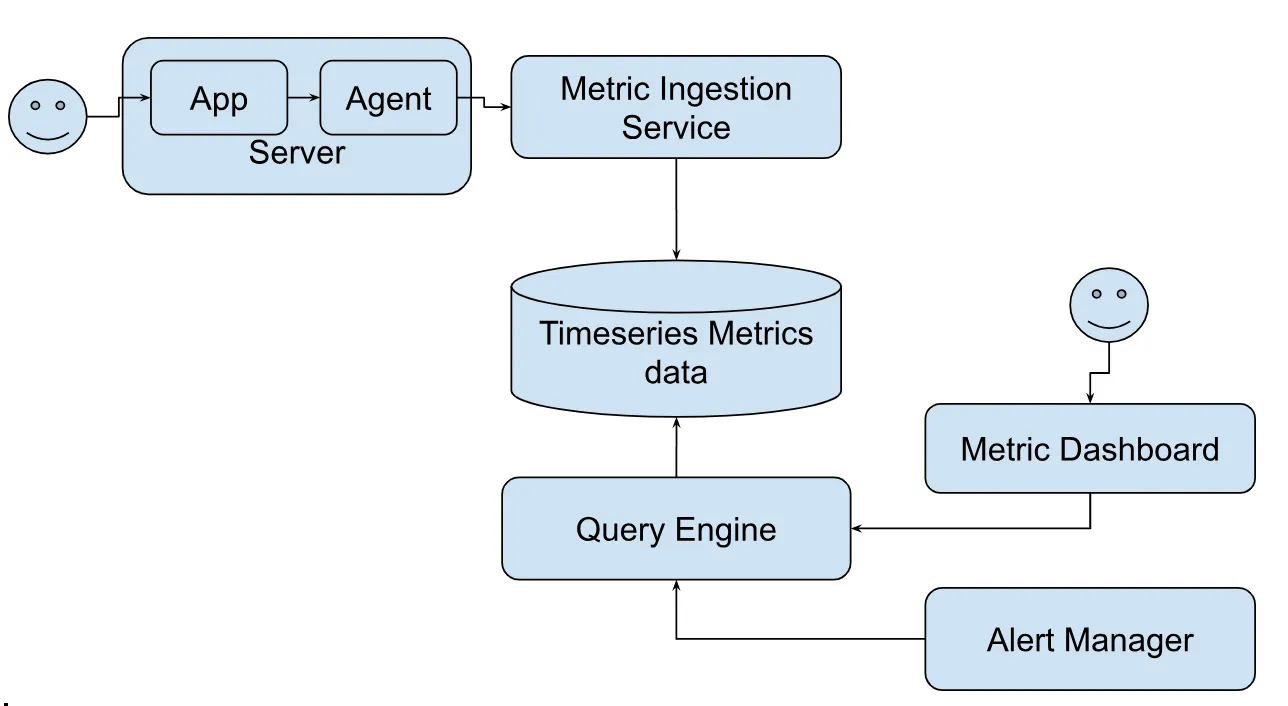
On high level we need following components.
- Data collection: Collect metrics data from different sources.
- Data transmission: Transfer data from sources to the metrics monitoring system.
- Data storage: Organize and store metrics timeseries data.
- Query Service: Query the metrics data
- Visualization: Visualize realtime and historical metrics data in various graphs and charts.
- Alerting: Run rules on the data and generate alert and send notifications to various communication channel.
Data collection and transmitting to monitoring system
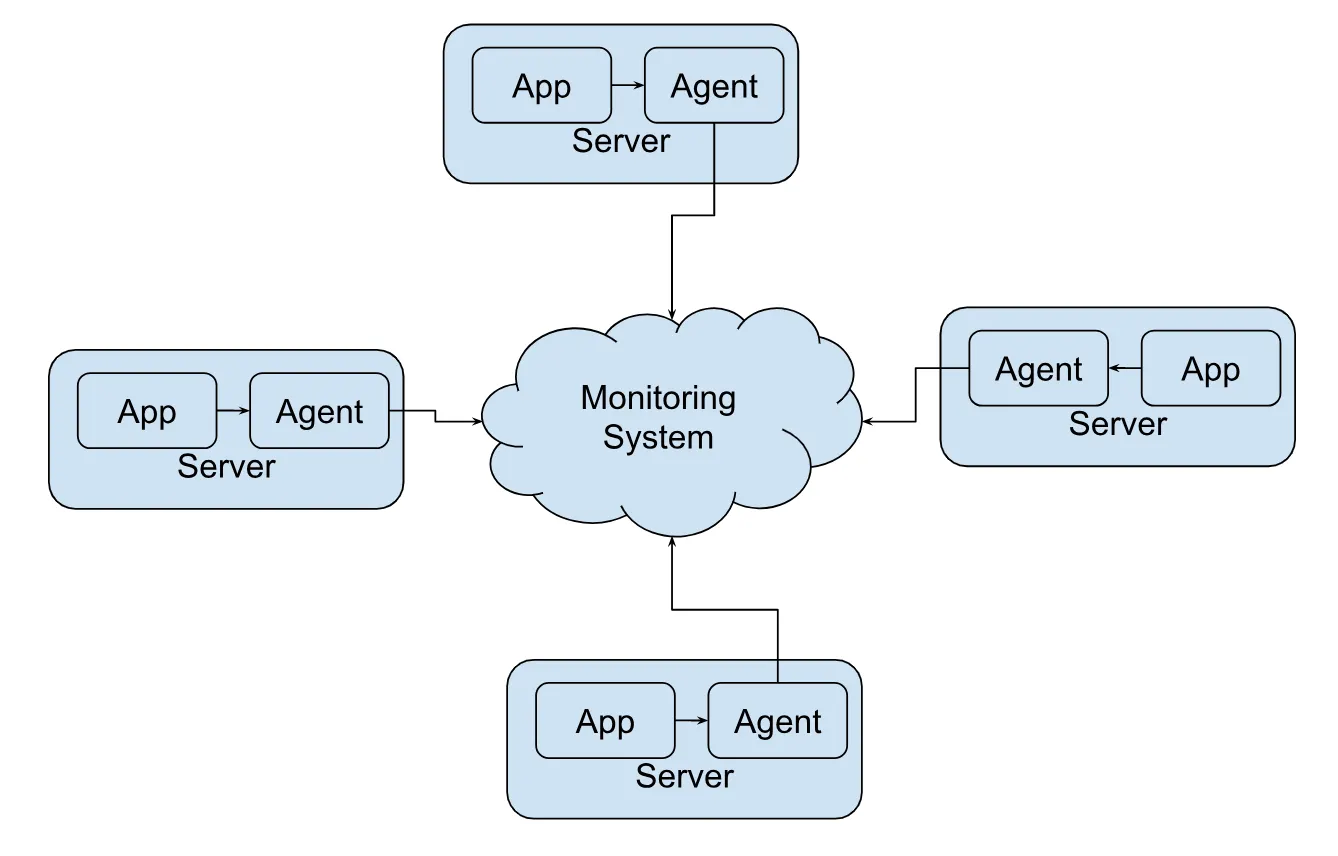
- App will be modified to emit metrics data.
- A metric agent will be installed on each servers which will be listening these metrics data.
- Agent will maintain the local buffer and when buffer is full then use UDP protocol to publish these metrics data in batch to the Monitoring system.
- UDP protocol is preferred here compare to TCP for low latency and risk of loosing data is ok.
Data model for storage
Metric data is emitted by source on a given timestamp which makes it a timeseries data.
We have following categories of data
- Server metadata: This includes server_user, job_name, machine_name, process_id etc.
- Metric metadata: This includes metric_name and any other custom tags for example client_type, language etc.
- Metric value: This represent the timeseries value of the metrics. It could be cumulative or non cumulative.
Every metric will be stored in it’s own table. Each row represents the stream of data for the given combination of server metadata and metric tags
Following is schema with example to understand the data model for metric /search/counter.
ServerUser JobName MachineName ProcessId ClientType Language /search/counter
xxxx yyyy zzzz 1 Web EN t1:xx,t2:xxx,t3:xx
xxxx yyyy zzzz 1 iOS EN t1:xx,t2:xxx,t3:xx
xxxx yyyy zzzz 1 Android EN t1:xx,t2:xxx,t3:xxSince values are emitted on certain interval by the application therefore it simply become streams of data emitted at different timestamp.
Following is example represent the streams of data for /search/counter.

- Each row represent the stream of data collected at timestamps with values.
- In this example values are incrementing (but could be not if data is different).
Types of stream data
Value of stream data can be of following types
- boolean
- int64
- double
- string
- tuple
- distribution
These can be categorized as below
- Non cumulative:
StringorBooleanare always non cumulative. A number can be non cumulative as well if it doesn’t represent value over time. For example RPC latency. - Cumulative: A metric whose value never decreases during the lifetime of a process. It only reset when the server restarts. For example a metric to count the number of times a function throws error then it will never decrease in the lifetime of process.
Distribution data type
Distributiondata type is unique for metric system.- It includes a histogram that partitions a set of double values into subsets called buckets.
- Each bucket keeps summarized values using overall statics such as sum, mean, count, standard deviation etc.
- It can also contains optional one-per-bucket exemplar for debugging purpose.
Following is example to show the difference between cumulative and non cumulative for Distribution data type.
Streams:(00:01,0.3)(00.01,0.5)(00.01,1.8)(00:02,0.3)(00:02,0.5)(00:02,2.7)
Non Cumulative distributions:
Bucket T0 T0+1m T0+2m
[0,1) 0 2 2
[1,2) 0 1 0
[2,4) 0 0 1
Cumulative distributions:
Bucket T0 T0+1m T0+2m
[0,1) 0 2 4
[1,2) 0 1 1
[2,4) 0 0 1Data storage system
Metric data is both schema typed as well as time series data. Since alerting system is going to rely on metrics storage therefore it must be fast and reliable.
Therefore better choice would be to use in-memory to store the data instead of writing on disk. We will also write on disk for recovery purpose.
Since it’s ok to loose few data therefore no need to wait for acknowledge while writing into recovery logs.
Intra zone setup
A highly scalable systems are installed on multiple zones to support the users across the geo location as well as better throughput and relibility purpose.
Metric system should also follow same. It should be deployed as one unit local to each zone. Local zone unit should be taking care of storing all the metric data. This greatly reduces ingestion fanout.
While running the query, it should perform search on all the available zones and return the response as single output.
This will also helps to keep producing metric data in case of any zone units failure.
Aggregation using bucket and admission window
Storage layer also maintains a sliding admission window. Once a bucket’s end time moves out of the admission window, the bucket is finalized: the aggregated point is written to the in-memory store and the recovery logs.
To handle clock skews, we can use TrueTime to timestamp deltas, buckets, and the admission window.
Query Engine

We need to build a Query engine to query the data for the given metric. This will read the timeseries database and return data needed for either alert or visualization.
Since data are stored across the zones with multiple nodes therefore every query needs to routed through leaf nodes finder to run the query on the data leaf nodes.
We can use the following SQL style to run the query.
{
fetch ComputeTask::/rpc/server/latency
| fitler user=="app-user"
| align delta(1h)
; fetch ComputeTask::/build/lable
| filter user=="app-user" && job="prod-00-us"
} | join
| group_by [label], aggregate(latency) Following is sample output of this query.

Sharding
The lexicographic sharding of data in a zone uses only the key columns corresponding to the target schema.
For example, the target string ComputeTask::sql-dba::db.server::aa::0876 represents the process of a database server. Target ranges are used for lexicographic sharding and load balancing among leaves; this allows more efficient aggregation across adjacent targets in queries.
Alerting system

Alert system has mainly four components
- Rules config: It has predefined rules to trigger alert based on metric evaluation.
- Alert manager: It periodically runs the rules and in case of anomalies it publish event to Queue to notifies customers.
- Alert Consumer: Alert consumers receives events from Queue and send the recipient based on available communication channel.
- Communication channel: Email, TextMessage, PageDuety, Webhooks are few communication channels.
Visualization system

Visualization is built on the top of Query engine. On high level it provides following.
- Load the data for given metrics
- Filter based on time range and other custom tags
- Graph to visualize the metrics data

Reference
Proposed system design is based on Google’s Monarch timeseries database. Feel free to read following paper to go deep about metrics and alerting system.
Enjoy designing big systems :-)
