Distributed Job Scheduler system design
Design a distributed job scheduler to reliably manage, track, and execute a high volume of user-submitted jobs in a scalable and fault-tolerant manner.
High level system design
Following is high level system design for Distributed Job scheduler.

Let’s go through each services in details.
Job Submission Service
Following is API to submit the job.
POST /jobs/submit
Request:{
UserId: xxx
IsRecurring: xx
Interval: xxx
MaxRetry: xx
}
Response:{
JobId:xx
}Job submission service will write toJobs table. Following is the schema of Jobstable with JobId as primary key with UserId as shard key.
UserId JobId IsRecurring Interval MaxRetry CreateTimestamp
1 1 True 0 */2 * * * 3 t1
1 2 True 0 */6 * * * 1 t2
1 3 True 0 0 * * * 0 t3
1 4 False NULL 3 t4
2 5 False NULL 3 t4Job submission will also analyze the job and enqueue into ScheduledJob queue with timestamp as delayed messages as per the interval defined for the job. Delayed message feature of Queue helps to process the message as per delay instead of immediately.ScheduledJob internally use following schema to store the schedule jobs .
{
ExecutionTimestamp: xx
Payload: {
JobId:xx
ExecutionTimestamp: xx
}
}ExecutionTimestamp will be the shard key. Timestamp based shard key helps queue system to pull colocated jobs at same time.
Scheduler Service
Scheduler service needs to make following two decision on receiving jobs to execute.
- If job is interval type then calculate the next execution time and re-enqueue back into
ScheduledJobqueue. - Analyze the job, it’s type, dependencies etc and allocate the right worker nodes to execute the job.
Workers
Based on jobs we can have various types of workers.
1. Idempotent workers
In the distributed system, it is fairly common that the duplicate messages can be delivered to workers due to retry or other reason. Therefore it is necessary that Workers are idempotent i.e. two workers can work on same job in parallel without impacting each other.
2. Non idempotent workers
Some time due to nature of job we don’t want multiple workers is working on same job. Goal here is to make sure if multiple workers receives the copy of same message then it should check with external storage to see the progress of job and based on either continue or drop it.

This is not a recommended approach. If possible redesign your task to keep it idempotent.
JobExecutionId Status
1 INPROGRESS3. Short running job
Shot running jobs are job which can be completed in few seconds therefore event can be acked to queue within it’s timeout limit.
4. Long running job
Sometime job may takes time to execute more than a minute or an hour.
None of the queue system can wait that long therefore event will be timed-out and redeliver to another worker. This lead to re-processing of same job at multiple workers and can never be completed.
There are many ways to handle long running job. It depends on the nature of job. Following are few ways.
Approach#1: Paginate the job processing
Sometime it’s easy to divide job scope into smaller chunk and then use it to paginate until job is completed.
This approach technically convert job into short processing job. Following Checkpoint table used as checkpoint to check the progress of the job.
JobExecutionId JobId PageSize PageStart IsCompleted TotalSize
1 1 10 20 False 3
2 1 10 0 False 3
3 1 10 100 True 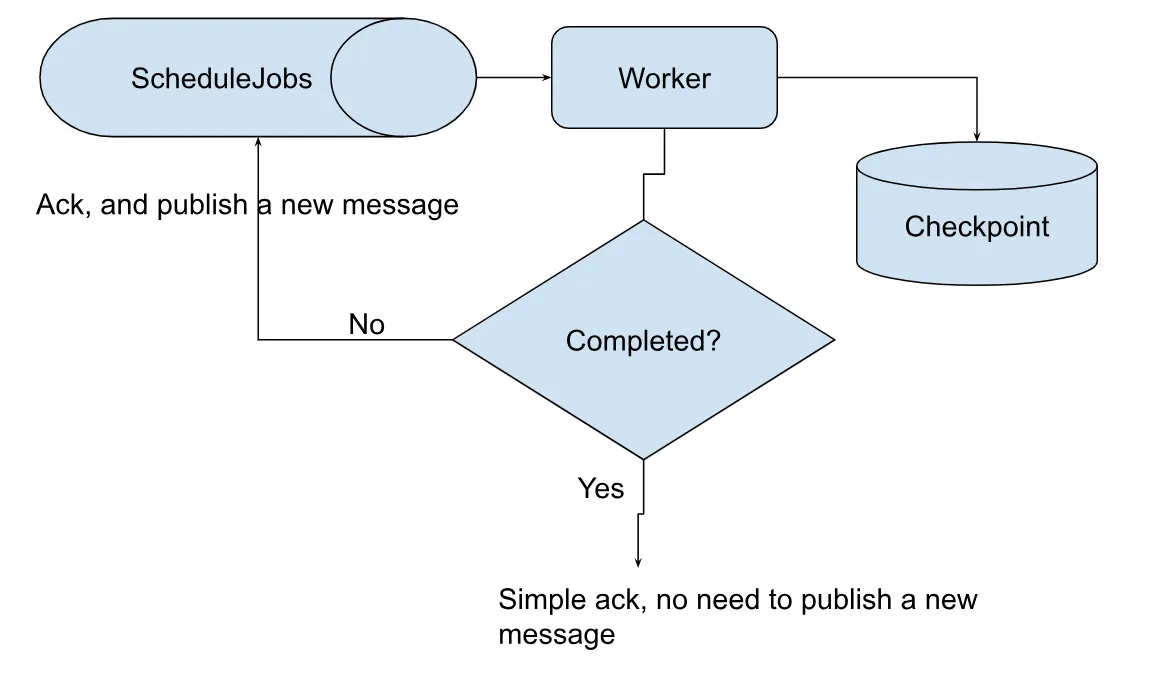
Based on the nature of task, these short processing jobs either can run sequentially or in parallel.
Sequential processing
- Worker will first look into
Checkpointtable to decide the chunk of work it needs to process. - Worker will only process the chunk of work as per given range.
- Worker will also find if more work is pending. If yes then it will enqueue new message with next page details and ack the current message. It will also update the chunk status in
Checkpointtable. - If Worker finds that no more chunk of work is pending then it will simply ack the message without enqueuing a new message. It will also update the chunk status in
Checkpointtable.
Parallel processing
- A new type of worker is required which will first identify the job that needs to be chunked and process in parallel.
- It will first split job into
nnumber of short processing job and submit all toScheduledJobsQueue to get process. - Now all the short processing jobs will be process in parallel.
- Check point table will be required to monitor the progress of overall processing of job.
- Worker will also check if job processing is completed or not. If completed then update the final JobStatus table.
Approach#2: Enqueue message for long future
If a job can’t he chunked into small tasks then we will need to maintain JobStatus table as below.
JobExecutionId Status
1 INPROGRESS
2 COMPLETEDFollowing is approach to handle this type of job.
- Manager
JobStatustable to check the processing status of job. - Worker will look into
JobStatustable to check the status of job processing. - If job is already completed then simply ack the message.
- Worker should estimate the time it may take to complete the job execution based on historical and job type.
- If Job status is in-progress then simply ack current message and enqueue a new message to queue with future estimated time.
- If Job was never started then as well ack the current message and enqueue and new message to queue with future estimated time. It will also start processing the job and update
Checkpointtable asINPROGRESS - When worker complete the processing then update the
Checkpointtable. - Once future enqueued message is redelivered by queue to any of the wroker then it will replay the above logic.
Retry mechanism
Based on the job’s configured retry-able option, worker node will decided to ack or nack message.
If job is eligible for retry then in case of failure, worker node will simply ack the message and publish a new message with incremented in the message.
If job is not eligible for retry then on failure, simply nack the message.
We can also implement exponential backoff. It means, on retry, enqueue next message with delay of 2^x minutes. I.e. on first retry, enqueue with 2minutes delay. On second retry, enqueue with 4 minutes delay. Next retry with 16 minutes delay. Next retry would be 256 minutes and so on.
Task execution history
Worker will also write task execution history on complete executing the job. Following is schema for TaskExecutionHistory
JobExecutionId JobId StartTime CompletedTime Status RetryCount Reporting Service
Reporting service will use the Jobs and TaskExecutionHistory table to show the status of jobs for each user.
Alerting and monitoring service
We can capture the error rate of job failure in the monitoring system. Then also configure rules to alert based on condition.
Scale job scheduler system
Based on volume of users and job we can horizontally scale the each components. Since storage are properly shard therefore horizontally scaling can be easily applied.
Reference Study
Read more about following
https://github.com/timgit/pg-boss
https://dolphinscheduler.apache.org/en-us/docs/3.2.1/architecture/design
A Comprehensive Study of “etcd” — An Open-Source Distributed Key-Value Store with Relevant Distributed Databases
Enjoy designing large scale system.
